|
|
|
|
 |
|
Première prédiction des propriétés du fond stochastique dâondes gravitationnelles dâorigine astrophysique |
|
|
| |
|
| |
Première prédiction des propriétés du fond stochastique d’ondes gravitationnelles d’origine astrophysique
vendredi 15 juin 2018
La détection des ondes gravitationnelles par les interféromètres LIGO et Virgo a ouvert une nouvelle fenêtre observationnelle en astrophysique. Une équipe de chercheurs de l’Institut d’Astrophysique de Paris (CNRS/Sorbonne Université), de l’université d’Oxford et de l’Institut Max-Planck pour la physique gravitationnelle a établi les propriétés des anisotropies du fond stochastique d’ondes gravitationnelles généré par toutes les sources astrophysiques non résolues. Elle présente dans la revue Physical Review Letters,
la première prédiction du spectre angulaire de cette nouvelle observable astrophysique. Ce travail ouvre un nouveau champ d’étude au croisement de la relativité générale, de l’astrophysique et de la cosmologie.
La détection directe des ondes gravitationnelles par LIGO et Virgo ouvre une nouvelle voie observationnelle en astrophysique. L’étude des quelques systèmes binaires de trous noirs et d’étoiles à neutrons observés lors de leur coalescence apporte déjà de nombreuses informations sur ces systèmes.
Chaque galaxie possède de nombreuses sources d’ondes gravitationnelles : systèmes binaires de trous noirs et d’étoiles à neutrons, trous noirs supermassifs, supernovae etc. La grande majorité de ces systèmes ont une puissance trop faible pour être individuellement détectée. Ces sources non‐résolues contribuent collectivement à la production d’un fond stochastique d’ondes gravitationnelles, similaire au fond diffus infrarouge produit par toutes les sources optiques non‐résolues.
Les propriétés de ce fond stochastique dépendent autant de la cosmologie (qui décrit l’évolution des grandes structures de l’univers) de l’histoire de formation des galaxies et de l’astrophysique. En effet, le taux cosmique de formation d’étoiles et le scénario d’évolution stellaire déterminent le taux de formation de trous noirs et d’étoiles à neutrons ainsi que l’abondance et l’évolution des systèmes binaires, cela en fonction du temps. En développant un modèle semi‐analytique, les chercheurs ont pu modéliser les différentes populations sources d’ondes gravitationnelles. Pour chacune d’entre elles, la relativité générale permet de décrire le rayonnement gravitationnel. Ainsi, ils ont pu calculer la luminosité en onde gravitationnelle des galaxies en fonction des caractéristiques de ces dernières (masse, fraction d’éléments chimiques complexes, âge). La cosmologie leur a ensuite permis de décrire la distribution des galaxies. Celle-‐ci dépend à la fois des conditions initiales sur les inhomogénéités de la distribution de matière générée dans l’univers primordial pendant la phase d’inflation et de leur évolution. En couplant leur modèle astrophysique à un modèle cosmologique, les chercheurs ont prédit les propriétés statistiques de ce fond d’ondes gravitationnelles, et en premier lieu son spectre de puissance angulaire dans différentes bandes de fréquence. Ils prédisent qu’à la fréquence de 100 Hz, les fluctuations du signal sont de l’ordre de 30% par rapport à sa valeur moyenne. Ils ont aussi établi une expression analytique de ce spectre aux grandes échelles angulaires. Ces informations sont capitales pour pouvoir détecter ce signal. Ce travail est l’aboutissement d’un programme de recherche développé à l’Institut d’Astrophysique de Paris où toute l’équipe travaillait jusqu’à la fin 2017.
Cette approche nécessite de coupler relativité générale, évolution stellaire, évolution des galaxies et cosmologie. Le signal prédit dépend de nombreux paramètres astrophysiques encore mal connus (distribution des systèmes binaires, fraction de trous noirs dans des systèmes binaires, évolution des galaxies, etc.). Cette étude laisse ainsi entrevoir une possibilité pour mesurer des paramètres inaccessibles autrement. Ce résultat ouvre de nombreuses perspectives en astrophysique, en particulier pour contraindre le taux de formation de systèmes binaires et de leur coalescence ou la répartition spatiale des trous noirs.
Les chercheurs ont aussi démontré que ce signal d’ondes gravitationnelles était corrélé à d’autres observables cosmologiques comme la distribution des galaxies et le effets de lentilles gravitationnelles faibles. Ces corrélations permettent de comparer entre elles la distribution de la matière visible (galaxies), de la matière noire (effets de lentilles gravitationnelles) et des trous noirs offrant une information inaccessible en astronomie optique.
L’amplitude de la densité moyenne du fond astrophysique stochastique d’ondes gravitationnelles a été contrainte par l’expérience LIGO et les expériences de chronométrage de pulsar, qui étudient aujourd’hui la possibilité de détecter les anisotropies aux grandes échelles angulaires. Le résultat publié est la première prédiction théorique sur laquelle peuvent s’appuyer ces développements.
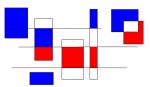
Spectre de puissance angulaire des fluctuations du fond stochastique d'ondes gravitationnelles. Crédits : C. Pitrou, JP. Uzan
Pour en savoir plus:
G. Cusin, I., C. Pitrou, et J.-P. Uzan, Anisotropy of the astrophysical gravitational wave background I: analytic expression of the angular power spectrum and correlation with cosmological observations, Phys. Rev. D 96, 103019 (2017)
I. Dvorkin, J.-P. Uzan, E. Vangioni, et J. Silk, A synthetic model of the gravitational wave background from evolving binary compact objects, Phys. Rev D 94, 103011 (2016)
Source(s):
G. Cusin, I. Dvorkin, C. Pitrou, et J.-P. Uzan, First prediction of angulat power spectrum of the astrophysical gravitational wave background, Phys. Rev. Lett (2018)
Contact(s):
* Cyril Pitrou, IAP (CNRS/Sorbonne Université)
* pitrou [at] iap [dot] fr, 01 44 32 80 00
* Jean-Philippe Uzan, IAP
* uzan [at] iap [dot] fr, 01 44 32 80 26
DOCUMENT CNRS LIEN
|
| |
|
| |
|
|
|
LA DÃMARCHE SCIENTIFIQUE |
|
|
| |
|
| |

LA DÉMARCHE SCIENTIFIQUE
Pour comprendre et expliquer le réel en physique, chimie, sciences de la vie et de la Terre, les scientifiques utilisent une méthode appelée la démarche scientifique. Quels sont ses grands principes ? Quels outils sont utilisés pour mettre en place des raisonnements logiques ? Découvrez l’essentiel sur la démarche scientifique.
QU’EST-CE QUE LA DÉMARCHE SCIENTIFIQUE ?
La démarche scientifique est la méthode utilisée par les scientifiques pour parvenir à comprendre et à expliquer le monde qui nous entoure. De façon simplificatrice, elle se déroule en plusieurs étapes : à partir de l’observation d’un phénomène et de la formulation d’une problématique, différentes hypothèses vont être émises, testées puis infirmées ou confirmées ; à partir de cette confirmation se construit un modèle ou théorie. L’observation et l’expérimentation sont des moyens pour tester les différentes hypothèses émises.
L’évolution de la démarche scientifique
au fil du temps
De l’Antiquité à nos jours, les moyens d’investigation sur le monde ont évolué pour aboutir à une démarche dont les fondements sont communs à toutes les sciences de la nature (physique, chimie, sciences de la vie et de la Terre).
Dès l’Antiquité, Hippocrate, médecin grec, apporte de la nouveauté dans son traité « Le pronostic », qui détaille, pour la première fois, un protocole pour diagnostiquer les patients. Ce texte est l’une des premières démarches scientifiques.
Le XVIIe siècle est l’âge d’or des instruments et désormais l'expérience est au cœur de la pratique scientifique : on parle de Révolution scientifique. En plus des observations, les hypothèses peuvent aussi être testées par l’expérience. Par ailleurs, l’invention d’instruments tels que le microscope donne la possibilité aux scientifiques d’observer des éléments jusqu’alors invisibles à l'œil nu, comme les cellules, découvertes par Robert Hooke en 1665.
A partir du XXe siècle, la science se fait de manière collective. Les études scientifiques sont soumises au jugement des « pairs », c’est-à-dire à d’autres scientifiques et toutes les expériences doivent être détaillées pour être reproductibles par d’autres équipes. En contrepartie, la publication dans des revues internationales, et sur Internet dès les années 1990, permet aux chercheurs du monde entier d’accroître la notoriété de leurs idées et facilite l'accès aux sciences pour le grand public. Mais avec l'arrivée de l'informatique, il n'y a pas que la communication qui change, la méthode scientifique aussi se transforme. Il devient plus simple de trier de grands nombres de données et de construire des études statistiques. Il faut cependant faire attention à sélectionner les critères pertinents, car les progrès technologiques apportent aux chercheurs d’immenses quantités d’informations, appelées big data.
LES DIFFÉRENTES ÉTAPES DE LA DÉMARCHE SCIENTIFIQUE
Observation et formulation d’une problématique
A la base de toute démarche scientifique,il y a au départ une observation d’un phénomène et la formulation d’une problématique.
Par exemple, depuis l’Antiquité, certains savants sont convaincus que la Terre est immobile au centre de l’Univers et que le Soleil tourne autour d’elle : c’est l’hypothèse du géocentrisme. Elle est émise car à l’époque, toutes les observations se faisaient à l’œil nu. Vu depuis la Terre, le Soleil peut donner l’impression de tourner autour de nous car il se lève sur l’horizon Est et se couche sur l’horizon Ouest. Cependant, ce n’était qu’une intuition car à ce stade, aucune véritable démarche scientifique n’est engagée.
Plus tard, quand les astronomes ont observé le mouvement des planètes, ils ont vu que le déplacement de certaines planètes forme parfois une boucle dans le ciel, ce qui est incompatible avec un mouvement strictement circulaire autour de la Terre. Le problème fut résolu en complexifiant le modèle : une planète se déplace sur un cercle dont le centre se déplace sur un cercle. C’est la théorie des épicycles.
Les hypothèses et la construction d’un modèle
Une nouvelle hypothèse fut émise par Nicolas Copernic au XVe siècle. Selon lui, le Soleil est au centre de l’Univers et toutes les planètes, dont la Terre, tournent autour de lui. On appelle cette hypothèse « l’héliocentrisme ». Ce modèle rend naturellement compte des rétrogradations planétaires mais possède quand même des épicycles pour décrire leurs mouvements avec plus de précisions.
Durant l’hiver 1609-1610, Galilée pointe sa lunette vers le ciel et découvre les phases de Vénus et des satellites qui tournent autour de la planète Jupiter. Ses observations l’incitent à invalider l’hypothèse géocentrique et à adhérer à l’héliocentrisme.
Petit à petit, cette méthode est devenue générale. Une hypothèse reste considérée comme valide tant qu’aucune observation ou expérience ne vient montrer qu’elle est fausse. Plus elle résiste à l’épreuve du temps, plus elle s’impose comme une description correcte du monde. Cependant, il suffit d’une seule observation contraire pour que l’hypothèse s’effondre, et dans ce cas, c’est définitif. Il faut alors changer d’hypothèse.
Reste que l’héliocentrisme de Copernic s’est d’abord imposé par la qualité des éphémérides planétaires qui en étaient tirées plus que par la force de son hypothèse, certes plus pratique que l’hypothèse géocentrique mais pas confirmée directement. Pour cela, il fallut encore attendre quelques années, le temps que la qualité des instruments d’observation progresse.
L’observation et l’expérimentation
Si la Terre est animée d’un mouvement autour du Soleil alors on devrait constater un effet de parallaxe, c’est-à-dire de variation des positions relatives des étoiles au fil de l’année. L’absence d’une parallaxe mesurable était utilisée contre l’héliocentrisme. C’est en cherchant à mesurer la parallaxe des étoiles que l’astronome anglais James Bradley découvrit en 1727 un autre effet, l’aberration des étoiles, dont il montra qu’elle ne pouvait provenir que de la révolution de la Terre autour du Soleil. La première mesure de parallaxe, due à l’astronome Friedrich Bessel en 1838, vient clore le débat.
Le mouvement de rotation de la Terre ne fut prouvé que plus tard. En 1851 le physicien Léon Foucault mène une expérience publique spectaculaire : un grand pendule est accroché à la voûte du Panthéon de Paris et la lente révolution de son plan d’oscillation révèle la rotation de la Terre sur elle-même.
On trouve là une autre caractéristique de la démarche scientifique. Une fois le modèle mis au point en s’appuyant sur des observations qui le justifient, il faut en tirer des prédictions, c’est-à-dire des conséquences encore non observées du modèle. Cela permet de mener de nouvelles observations ou de bâtir de nouvelles expériences pour aller tester ces prédictions. Si elles sont fausses, le modèle qui leur a donné naissance est inadéquat et doit être réformé ou oublié. Si elles sont justes, le modèle en sort renforcé car il est à la fois descriptif et prédictif.
La communication
Aujourd’hui, la « revue par les pairs » permet de contrôler la démarche scientifique d’une nouvelle découverte, par un collège de scientifiques indépendants. Si les observations et expérimentations vont dans le même sens et qu’elles ne se contredisent pas, la proposition est déclarée apte à être publiée dans une revue scientifique.
QUELS OUTILS POUR DÉCRYPTER
LA SCIENCE ?
La démarche scientifique repose sur la construction d’un raisonnement logique et argumenté. Elle utilise les bases de la logique formelle : l’induction et la déduction.
L’induction
L’induction cherche à établir une loi générale en se fondant sur l’observation d’un ensemble de faits particuliers (échantillon).
L'induction est par exemple utilisée en biologie. Ainsi, pour étudier des cellules dans un organisme, il est impossible de les observer toutes, car elles sont trop nombreuses. Les scientifiques en étudient un échantillon restreint, puis généralisent leurs observations à l’ensemble des cellules. Les scientifiques établissent alors des hypothèses et des modèles dont il faudra tester les prédictions par des observations et des expériences ultérieures.
La déduction
La déduction relie des propositions, dites prémisses, à une proposition, dite conclusion, en s’assurant que si les prémisses sont vraies, la conclusion l’est aussi.
Exemple classique de déduction : tous les hommes sont mortels, or Socrate est un homme donc Socrate est mortel.
La déduction est beaucoup utilisée en physique ou mathématiques, lors de la démonstration d’une loi ou d’un théorème.
Raisonnement du Modus Ponens et du Modus Tollens
Le Modus Ponens et le Modus Tollens sont utilisés par les scientifiques dans leurs raisonnements.
Le Modus Ponens est, en logique, le raisonnement qui affirme que si une proposition A implique une proposition B, alors si A est vraie, B est vraie.
Mais si une implication est vraie alors sa contraposée l’est également (même valeur de vérité selon les règles de la logique formelle). Cela signifie que « la négation de B implique la négation de A » (contraposée de « A implique B »).
Le Modus Tollens est le raisonnement suivant : si une proposition A implique une proposition B, constater que B est fausse permet d’affirmer que A est fausse.
Un exemple : On sait que tous les poissons respirent sous l'eau. Or le saumon est un poisson donc il respire sous l'eau (Modus Ponens). La proposition initiale peut être énoncée sous une autre proposition équivalente (contraposée) : si « je ne peux pas respirer sous l’eau, alors je ne suis pas un poisson ». Cela permet de construire le raisonnement suivant : tous les poissons respirent sous l’eau, or je ne respire pas sous l’eau, donc je ne suis pas un poisson (Modus Tollens).
DOCUMENT cea LIEN |
| |
|
| |
|
|
|
ALAN MATHISON TURING |
|
|
| |
|
| |

Alan Mathison Turing
Mathématicien britannique (Londres 1912-Wilmslow, Cheshire, 1954).
Il fut un brillant logicien (→ logique) et l'un des pionniers de l'informatique et de l'intelligence artificielle.
1. De la logique mathématique à l'informatique
Fils d'un officier de l'armée des Indes, Alan Turing, âgé d'à peine 1 an, est confié à un couple de retraités qui va l'élever, ainsi que son frère John. Sa mère part, en effet, rejoindre son père, administrateur colonial à Madras. Ses parents ne regagneront définitivement l'Angleterre qu'en 1926 (mais reverront leurs enfants chaque année lors des vacances).
Réfractaire à la scolarité, le jeune Alan manifeste un désintérêt total pour les matières littéraires, mais un goût prononcé pour les disciplines scientifiques, en particulier pour la chimie, et de réelles dispositions pour les mathématiques. En 1931, il est admis au King's College de Cambridge pour y poursuivre des études de mathématiques ; il y obtient sa licence en 1934. Ses lectures ainsi que les cours du mathématicien Max Newman (1897-1984) et de l'astrophysicien Arthur Eddington lui font découvrir les grandes questions de la science moderne.
Les travaux de David Hilbert sur la recherche des fondements des mathématiques et ceux de Johann von Neumann sur les fondements mathématiques de la mécanique quantique stimulent son intérêt pour l'étude du déterminisme en physique et en mathématiques. Chargé de cours au King's College en 1935, il part l'année suivante à Princeton, aux États-Unis, préparer un doctorat de logique mathématique sous la direction d'Alonzo Church (1903-1995). Après avoir soutenu sa thèse, il regagne Cambridge, en juillet 1938.
L'un des problèmes qu' étudie Turing est celui, posé par Hilbert, de la possibilité pour une proposition mathématique d'être validée comme vraie ou fausse par un algorithme. Un article rédigé avant son départ aux États-Unis, mais publié seulement en janvier 1937, On Computable Numbers, with an Application to the Entscheidungsproblem (Sur les nombres calculables, avec une application au problème de la décision), constitue l'une de ses plus importantes contributions à la logique mathématique. L'auteur y élabore le concept d'une machine à calculer « universelle » (machine de Turing), qui est à la base de toutes les théories sur les automates et ouvre la voie à de nombreux développements de la théorie des algorithmes. Une opération n'est exécutable sur ordinateur que s'il existe une machine de Turing équivalente. Tous les ordinateurs étant des réalisations matérielles de cette machine universelle, Turing peut être considéré comme le fondateur de l'informatique.
2. Cryptologie, ordinateurs, intelligence artificielle
Pendant la Seconde Guerre mondiale, Turing contribue à l'effort allié, au sein du service britannique du chiffre, en mettant au point des machines et des méthodes qui lui permettent de percer les codes secrets de la machine Enigma utilisée par la marine allemande pour communiquer avec ses sous-marins (→ cryptographie). Envoyé secrètement aux États-Unis, il travaille aux Laboratoires Bell de New York (1943), où il rencontre régulièrement Claude Elwood Shannon, l'un des fondateurs de la théorie de l'information, avec qui il évoque des projets de machines qui imiteraient le fonctionnement du cerveau humain. Après son retour en Angleterre, il conçoit et réalise une machine électronique capable de crypter la voix humaine.
En 1945, il reprend ses recherches sur la conception des machines à calculer au Laboratoire national de physique britannique. Le projet de construction d'un calculateur électronique qu'il présente en 1946 marque, avec celui proposé quelques mois auparavant aux États-Unis par John von Neumann, l'acte de naissance de l'ordinateur. En 1947, Turing retourne au King's College et prend une année sabbatique pour suivre des cours de physiologie et de neurologie. Son intérêt pour les phénomènes de croissance animale ou végétale se développe ; ils deviendront son champ de recherche à partir de 1951. À l'automne 1948, il rejoint l'équipe d'informatique de l'université de Manchester et, durant les deux années suivantes, se consacre à des travaux de programmation électronique, tout en s'intéressant à l'intelligence artificielle.
En 1951, il est élu membre de la Royal Society. Cependant, la révélation de son homosexualité va bientôt briser sa carrière. Arrêté et inculpé en 1952 à la suite d'une aventure avec un jeune homme, il évite la prison en acceptant de subir un traitement de castration chimique, mais il est écarté des grands projets gouvernementaux. Le 7 juin 1954, sa femme de ménage le trouve mort, dans son lit, et remarque une pomme à moitié mangée posée sur sa table de chevet. L'enquête établit que le fruit a macéré dans du cyanure et conclut à un suicide par empoisonnement. La mère d'Alan Turing écartera pourtant cette thèse et soutiendra celle de l'accident, en arguant que son fils avait l'habitude d'entreposer chez lui des produits chimiques sans aucune précaution.
Suite aux nombreuses pétitions réclamant la réhabilitation de Turing, la reine Elizabeth II le gracie en 2013. Le gouvernement britannique considère aujourd'hui sa condamnation comme injuste et discriminatoire et salue son génie qui a contribué à sauver des milliers de vie. Depuis 1966, le prix Turing récompense chaque année une personne ayant apporté une contribution significative au monde de l'informatique. En 2015, la biographie d'Alan Turing est portée à l'écran dans le film Imitation Game.
DOCUMENT larousse.fr LIEN |
| |
|
| |
|
|
|
CRYPTOGRAPHIE |
|
|
| |
|
| |

PLAN
* CRYPTOGRAPHIE
* Principes généraux
* Historique
* Les principales techniques
* La cryptographie à clé secrète
* La cryptographie à clé publique
* La cryptographie quantique
cryptographie
Consulter aussi dans le dictionnaire : cryptographie
Ensemble des techniques de chiffrement qui assurent l'inviolabilité de textes et, en informatique, de données.
Principes généraux
Un système de cryptographie adopte des règles qui définissent la manière dont les données sont encryptées ou décryptées. On distingue les techniques sans clé et celle à une ou deux clés. Une clé est une suite de bits qui sert au chiffrement et au déchiffrement des données. La clé est souvent produite à partir d'un mot (ou d'une phrase) de passe. Un algorithme qui n'utilise pas de clé n'offre une sécurité que tant qu'il demeure secret. Dans une méthode à base de clé, la protection ne dépend pas de l'algorithme de chiffrement, qui peut être largement divulgué, mais de la confidentialité de la clé. Les systèmes n'ayant qu'une seule clé s'en servent pour les deux sens, tandis que ceux qui en ont deux utilisent l'une, dite clé publique, au chiffrement et l'autre, dite clé révélée, au déchiffrement.
Historique
La cryptographie était déjà utilisée dans l'Antiquité romaine : Jules César la pratiquait dans certains messages en décalant chaque lettre de quatre rangs par rapport à sa place dans l'alphabet. Les premiers traités de chiffrement combinatoire remontent au ixe s. et sont l'œuvre du philosophe et savant arabe al-Kindi. Après lui, les hommes de la Renaissance ont poursuivi l'étude de cet art du message secret, dont l'intérêt politique ne leur avait pas échappé. Mais il a fallu attendre la Seconde Guerre mondiale pour que la cryptographie accède à une autre dimension. Pour garantir le secret des messages signalant la position de ses sous-marins, l'Allemagne nazie avait mis au point la machine de cryptage Enigma. Dans un message codé, le chiffrement d'une lettre n'était pas fixe, mais suivait une loi de fluctuation dont les combinaisons étaient si nombreuses qu'elle décourageait toute tentative de décryptage. Pour pallier cet obstacle, les Alliés firent appel à des mathématiciens (dont Alan Turing) pour construire des machines capables de suivre automatiquement les variations de ces codes. Ce travail eut pour conséquence inattendue de contribuer à la naissance de l'ordinateur.
Plus récemment, l'expansion considérable des réseaux a conduit la cryptographie à sortir du champ strictement militaire ou diplomatique. Afin de garantir la confidentialité des messages et de conditionner l'accès à certaines informations circulant sur les réseaux, les informaticiens ont développé des techniques de cryptage utilisant des théories mathématiques sophistiquées. Aujourd'hui, le développement du commerce électronique conduit même à une légalisation de la cryptographie privée.
Les principales techniques
Selon le concept et le mode de fonctionnement mis en œuvre, les systèmes de cryptographie modernes relèvent de deux grandes techniques : la cryptographie à clé secrète (ou privée) et la cryptographie à clé publique (ou à double clé). Il faut y ajouter la cryptographie quantique, à la pointe des recherches menées pour accroître encore la sécurité.
La cryptographie à clé secrète
Dans cette technique, la clé qui sert au cryptage des informations par l'expéditeur d'un message est identique à celle qui permet leur décryptage par le destinataire. L'algorithme de chiffrement à clé secrète le plus répandu est le DES (sigle de l'anglais Data Encryption Standard). Développé en 1976, par une équipe d'IBM, pour le National Bureau of Standards, il a été adopté à cette époque comme standard de chiffrement aux États-Unis et certaines de ses variantes restent largement utilisées, notamment dans le secteur bancaire (cartes de crédit). Son principal avantage est une vitesse de chiffrement et de déchiffrement très élevée. Mais le fait que l'expéditeur et le destinataire utilisent la même clé n'est pas sans risque ; ils doivent en effet se la communiquer à un moment ou à un autre, et son interception par un tiers est toujours possible.
La cryptographie à clé publique
Dans cette technique, la clé qui sert à chiffrer le message diffère de celle utilisée pour son déchiffrement. Le logiciel de cryptage d'un utilisateur génère ainsi deux clés distinctes. La première, dite clé publique, est publiée dans un annuaire accessible à tous sur Internet. La seconde, dite clé privée, est gardée secrète. L'expéditeur d'un message doit au préalable consulter l'annuaire en ligne pour y trouver la clé publique associée au destinataire. Il l'utilise ensuite pour crypter son message. Le destinataire ne peut décrypter le message qu'à l'aide de la clé qu'il a tenue secrète. Le cryptage est dit asymétrique, car l'expéditeur lui-même n'est pas en mesure de décrypter son message, une fois celui-ci codé.
L'algorithme de chiffrement à clé publique le plus répandu est RSA, ainsi nommé d'après les initiales des noms des trois chercheurs du Massachusetts Institute of Technology qui l'ont mis au point en 1977, Ronald Rivest, Adi Shamir et Len Adleman. Sa fiabilité tient à la difficulté qu'éprouvent les mathématiciens à factoriser les très grands nombres premiers : s'il est facile, à l'aide d'un ordinateur, de faire le produit de deux nombres premiers de plus de cent chiffres, il est en revanche extrêmement compliqué, à partir du résultat du produit, de trouver les deux facteurs qui en sont à l'origine. RSA tire parti de cette difficulté : un texte est codé en fonction d'un certain nombre n, connu de tous (clé publique), composé de deux entiers premiers p et q que tout le monde ignore à l'exception du destinataire (clé privée), et qui lui permettent de décoder le message. Si n est un nombre assez grand, le système est pratiquement inviolable, compte tenu du temps nécessaire aux machines les plus puissantes pour retrouver p et q. À l'heure actuelle, lorsque la clé a une longueur d'au moins 1 024 bits, le système est considéré comme sûr.
L'algorithme RSA est utilisé aujourd'hui dans une large variété d'appareils pour le chiffrement des communications et dans le cadre de la signature numérique, car il dispose d'une fonction d'authentification de l'émetteur du message. Il a toutefois l'inconvénient d'être 500 fois plus lent que le système DES. Aussi, pour l'envoi de messages confidentiels longs, recourt-on fréquemment à une méthode mixte alliant la sécurité de la cryptographie à clé publique à la rapidité de la cryptographie à clé secrète. La plus connue de ces méthodes est PGP (sigle de l'anglais Pretty Good Privacy), inventée en 1992 par l'Américain Phil Zimmermann.
La cryptographie quantique
Sur le réseau Internet, ni la cryptographie à clé publique, ni celle à clé secrète ne permettent de savoir si le message chiffré émis n'a pas été intercepté par une personne autre que le destinataire. Cet inconvénient disparaît avec la cryptographie quantique. Celle-ci s'appuie sur la physique quantique, d'où son nom. Plus précisément, elle tire parti du principe d'incertitude de Heisenberg, selon lequel le seul fait de mesurer un système quantique suffit à perturber ce dernier.
Dans la cryptographie quantique, on transmet des impulsions lumineuses, par l'intermédiaire de fibres optiques. Le texte du message codé sous forme de bits est représenté par un ensemble de photons dont l'état quantique correspond à la valeur de ses bits. Si, lors de la transmission, un intrus agit sur l'un des photons, il en détruit la polarisation, de sorte que l'expéditeur et le destinataire s'en aperçoivent immédiatement.
Cette technique permet donc l'échange d'informations confidentielles, notamment celui de la clé de codage employée dans un système à clé publique. Elle se heurte toutefois à un problème important, celui de l'atténuation progressive du flux de photons le long des fibres optiques par lesquelles ils transitent. Au-delà de quelques kilomètres, la cryptographie quantique devient inopérante.
DOCUMENT larousse.fr LIEN |
| |
|
| |
|
| Page : [ 1 2 3 4 5 6 7 8 9 10 ] - Suivante |
|
|
|
|
|
|